Fuzzy Match in Elasticsearch
Introduction
A fuzzy search refers to find matches to a pattern that match approximately according to some criteria. Elastic search supports fuzzy matching using an algorithm called Levenshtein edit distance.
An edit distance is the total number of adds, deletes, replaces or transposes (a.k.a edits) required at each character of a pattern for it to match the search term. Some examples below.
-
for Austria to match Australia, we need 2 adds: (Austr
+al+ia) -
for dog to turn into a fox, we need 2 deletes and 2 adds:(
-d+fo-g+x) -
turning china into chile requires 2 adds and 2 deletes: (chi
-n-a+l+e).
Now that you get the hang of the fuzzy match, let us look into how Elastic search does it.
Fuzzy Matching in Elasticsearch
When performing a fuzzy search in Elasticsearch, you can specify the fuzziness which is the edit distance above, along with the text to search for in value.
{
"query": {
"bool": {
"must": [
{
"fuzzy": {
"Country Name": {
"fuzziness": 3,
"value": "china"
}
}
}
]
}
},
"from": 0,
"size": 25
}Matches found include China, Chile and Ghana, along with other entries that include China in the name (Hong Kong SAR, China and Macao SAR, China).
"hits" : [
{
"_index" : "diabetes-prevalence.csv",
"_type" : "doc",
"_id" : "39",
"_score" : 5.3243513,
"_source" : {
"Country Name" : "China",
"Country Code" : "CHN",
"Indicator Name" : "Diabetes prevalence (% of population ages 20 to 79)",
"Indicator Code" : "SH.STA.DIAB.ZS",
"1960" : "",
"2017" : 9.74
}
},
{
"_index" : "diabetes-prevalence.csv",
"_type" : "doc",
"_id" : "145",
"_score" : 3.44447,
"_source" : {
"Country Name" : "Macao SAR, China",
"Country Code" : "MAC",
"Indicator Name" : "Diabetes prevalence (% of population ages 20 to 79)",
"Indicator Code" : "SH.STA.DIAB.ZS",
"1960" : "",
"2017" : null
}
},
{
"_index" : "diabetes-prevalence.csv",
"_type" : "doc",
"_id" : "38",
"_score" : 3.1946108,
"_source" : {
"Country Name" : "Chile",
"Country Code" : "CHL",
"Indicator Name" : "Diabetes prevalence (% of population ages 20 to 79)",
"Indicator Code" : "SH.STA.DIAB.ZS",
"1960" : "",
"2017" : 8.46
}
},
{
"_index" : "diabetes-prevalence.csv",
"_type" : "doc",
"_id" : "82",
"_score" : 3.1946108,
"_source" : {
"Country Name" : "Ghana",
"Country Code" : "GHA",
...Specifying prefix_length
Sometimes we need to find matches that match from the beginning with fuzziness applied to the later part of the pattern. This might be to avoid hits such as Ghana for Chine. In this case, we set the prefix_length to 2 to indicate the first two characters must be matched.
{
"query": {
"bool": {
"must": [
{
"fuzzy": {
"Country Name": {
"fuzziness": 3,
"prefix_length": 2,
"value": "china"
}
}
}
]
}
},
"from": 0,
"size": 25
}We now have eliminated Ghana as a match due to the prefix_length since Ghana does not start with Ch. Chile is however included since it matches the fuzziness specified.
"hits": [
{
"_score": 6.3243513,
"_type": "doc",
"_id": "39",
"_source": {
"1960": "",
"Country Code": "CHN",
"Indicator Code": "SH.STA.DIAB.ZS",
"Country Name": "China",
"Indicator Name": "Diabetes prevalence (% of population ages 20 to 79)",
"2017": 9.74
},
"_index": "diabetes-prevalence.csv"
},
{
"_score": 4.1946106,
"_type": "doc",
"_id": "38",
"_source": {
"1960": "",
"Country Code": "CHL",
"Indicator Code": "SH.STA.DIAB.ZS",
"Country Name": "Chile",
"Indicator Name": "Diabetes prevalence (% of population ages 20 to 79)",
"2017": 8.46
},
"_index": "diabetes-prevalence.csv"
},
{
"_score": 3.9276366,
"_type": "doc",
"_id": "95",
...Fuzzy Match using Argon
Argon supports easy fuzzy searching on a field. It is done as follows:
1. Select the table to load in the Explorer View.
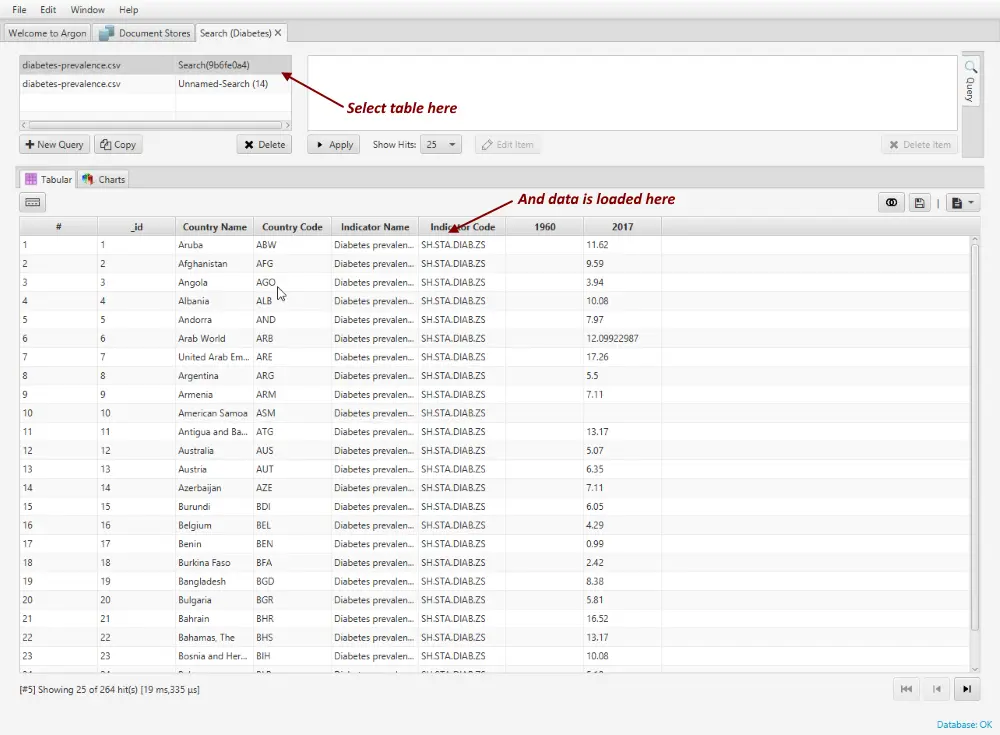
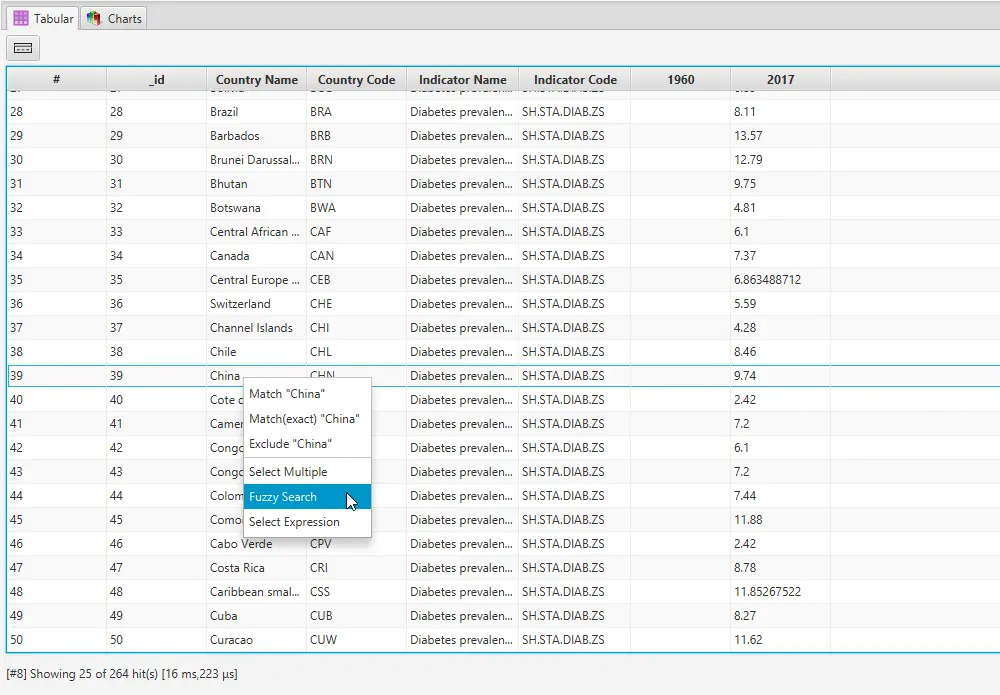
2. Pull up the context menu over a value and choose Fuzzy Search.
3. Adjust the fuzzy search parameters if necessary.
-
Changed the Max Edit Distance to
3. -
Changed Exact Match .. to
2
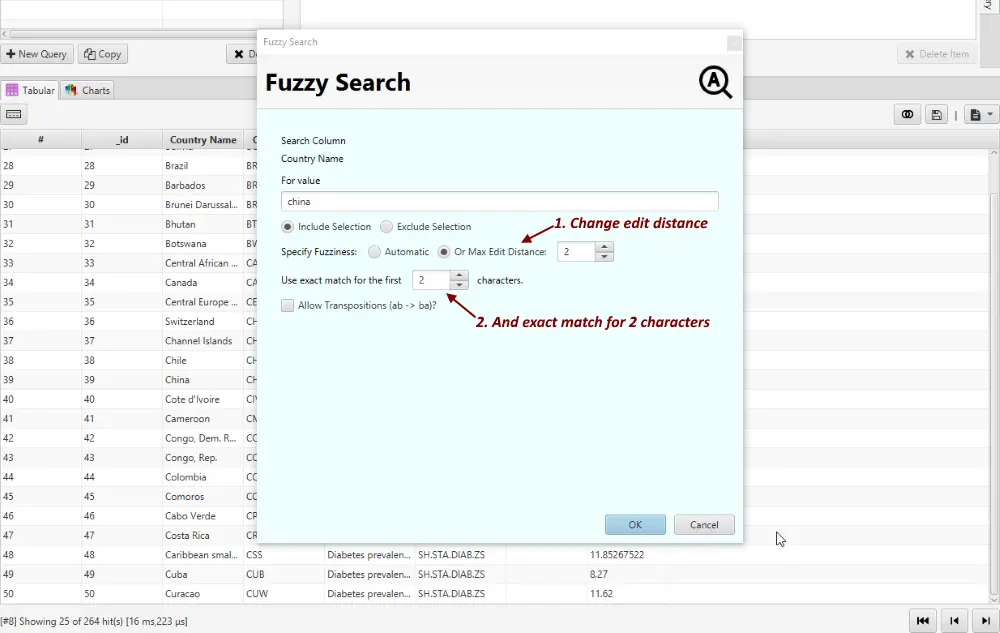
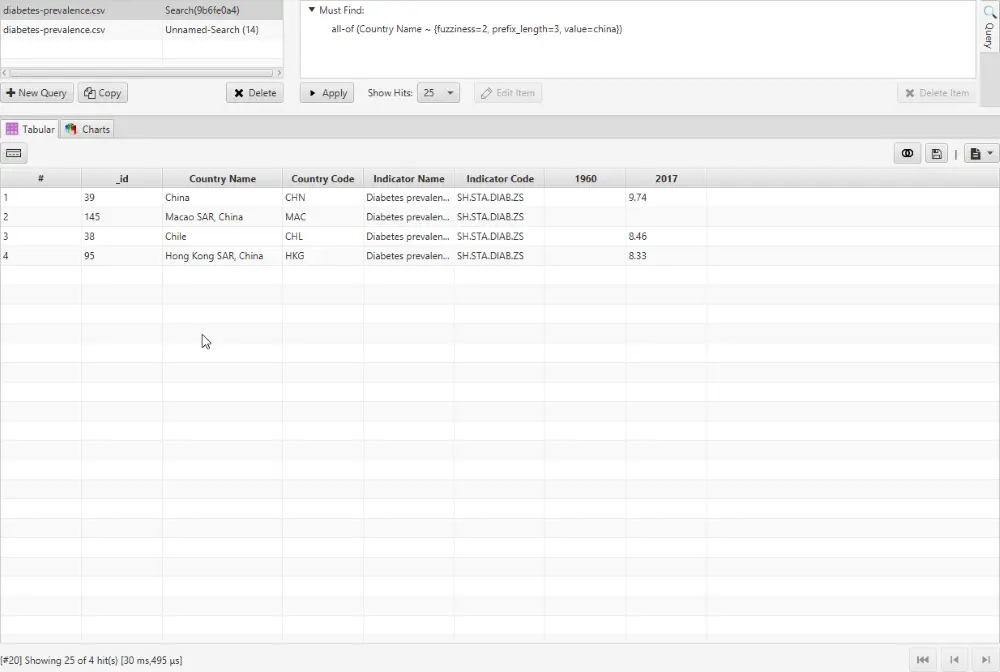
4. Click OK and the search is performed.
Try It Now with Argon
-
Elasticsearch Included Argon includes a recent version of Elasticsearch, so when you download and install it, an Elasticsearch database is ready.
-
Easy CSV Import Easily import CSV with automatic field type recognition.
-
Run Fuzzy Searches on Your Data Intuitive UI. No coding required.